Si hace unos meses os mostraba cómo crear conexiones VPN entre máquinas Linux y Windows con autentificación a través de servidor Radius y MySQL hoy veremos cómo aprovechar la misma estructura para autentificar usuarios que se conecten a nuestra red wifi de manera que tengamos todo el entorno de acceso a nuestra red integrado. En capítulos posteriores puede que veamos cómo añadir más servicios.
Ante todo aviso que no soy ningún experto en la materia y puede que diga cosas que no son correctas 😛 , por favor, no dudéis en corregirme.
La parte más importante del sistema la tenemos ya preparada, si necesitas montar todo el servidor Radius puedes leer el artículo anterior donde se explica bien el procedimiento. En esta ocasión nos centraremos en hacer que el servidor Radius que ya teníamos autentifique a los usuarios que se conecten a nuestro punto de acceso inalámbrico.
En un escenario normal es el punto de acceso el que se encarga de autentificar al cliente que intenta conectarse a través de las conocidas contraseñas (técnicamente shared-keys) con el inconveniente de que todos los usuarios deben utilizar la misma y si hay que cambiarla hay que comunicar a todos ellos cual es la nueva.
Hay dos conceptos dentro de todo este sistema que van siempre juntos pero son distintos:
- La encriptación de la comunicación entre el cliente y el punto de acceso, las conocidas WEP, WAP y WAP2.
- La shared-key de acceso al router.
Estos dos elementos son completamente independientes. No me voy a meter técnicamente en los distintos tipos de encriptación ya que no son el objetivo del artículo y hay toda la documentación que quieras al respecto. Para nuestro ejemplo vamos utilizar WPA2 con cifrado AES. Recuerda que estos parámetros sólo importan al punto de acceso y al cliente que se conecta, se utiliza para asegurar el canal inalámbrico, el servidor Radius es completamente ajeno a estos mecanismos.
En nuestro escenario el procedimiento descrito anteriormente quedaría como muestra este gráfico.

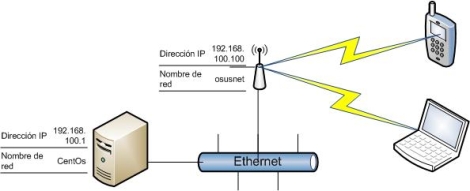{kind=link}
Es decir, para que un cliente se conecte a nuestro punto de acceso necesitará las credenciales adecuadas. Una vez el AP las recibe, consulta al servidor Radius si son correctas y debe dejarle pasar, en cuyo caso el cliente ya puede acceder a nuestra red. Cómo os habréis dado cuenta, entre el AP y Radius no he nombrado en ningún momento WAP2 o AES, éstos se utilizan sólamente en lo que en el gráfico superior es el rayo amarillo, el medio inalámbrico. En resumen, la diferencia entre la configuración habitual con shared-key estática y ésta es que permitimos que cada usuario tenga su login independiente, pudiendo cancelar su acceso en cualquier momento, algo que puede ser muy útil en ciertos ambientes, sobre todo corporativos.
Configurando el servidor Radius
Nuestro servidor Radius ya estaba configurado, sólo deberemos hacer un par de modificaciones. Primero añadimos permiso para que se conecte el punto de acceso y pueda autentificar a los clientes, para ello agregamos lo siguiente al archivo /etc/raddb/clients.conf:
client 192.168.100.100 {
secret = clavesecreta
shortname = osusnet
}
Donde la ip es la del AP, secret es la contraseña que utilizará el AP para conectarse a Radius y shortname un identificador interno. A continuación editamos el archivo /etc/raddb/eap.conf dejando las siguientes secciones de este modo:
default_eap_type = peap
tls {
private_key_password = whatever
private_key_file = ${raddbdir}/certs/cert-srv.pem
certificate_file = ${raddbdir}/certs/cert-srv.pem
CA_file = ${raddbdir}/certs/demoCA/cacert.pem
dh_file = ${raddbdir}/certs/dh
random_file = ${raddbdir}/certs/random
}
peap {
default_eap_type = mschapv2
}
Eap es el método de autenticación que se utilizará, en el caso que tratamos será PEAP (conocido también como EAP-MSCHAPv2) y necesita además TLS, por eso debemos añadir los dos en la configuración de Radius. En mi caso, la instalación de FreeRadius crea los certificados necesarios así que no entraré más en detalle sobre este tema, supondremos que existen y funcionan bien. Ya solo queda reiniciar el demonio Radius para que los cambios comiencen a estar visibles.
Configurando el punto de acceso
En este punto hemos terminado la configuración en nuestro servidor Linux. Configuraremos ahora el router, en mi caso un SMC. Tendremos que utilizar un cable ethernet para acceder al router ya que no podremos entrar por wifi hasta que lo tengamos bien configurado. La configuración en tu router será muy parecida a ésta. En las opciones “Wireless” le indicamos que la seguridad será WPA:

En la configuración WPA especificamos los parámetros que hemos acordado, WPA2 y AES. Además le indicamos que no utilizaremos pre-shared key para autenticación sino que se hará a través del protocolo 802.1x. Los demás parámetros no nos importan.
 Finalmente configuramos las opciones de autenticación 802.1x habilitándola e indicando la dirección IP de nuestro servidor Linux con Radius.
Finalmente configuramos las opciones de autenticación 802.1x habilitándola e indicando la dirección IP de nuestro servidor Linux con Radius.
 Ya está el router configurado. Sólo nos queda hacer lo propio con nuestro cliente inalámbrico. Como hemos escogido WAP2 supondremos que la tarjeta wireless del portátil la soporta, si no ¿por qué la has escogido? 😛 .
Ya está el router configurado. Sólo nos queda hacer lo propio con nuestro cliente inalámbrico. Como hemos escogido WAP2 supondremos que la tarjeta wireless del portátil la soporta, si no ¿por qué la has escogido? 😛 .
Configurando los clientes inalámbricos
Al buscar las redes inalámbricas disponibles en el portátil veremos la del router que hemos configurado. Por defecto no podremos acceder a ella, debemos indicarle cómo debe autenticarse, para ello vamos a “Configuración avanzada” y en la lista de redes seleccionamos la que nos ocupa y vamos a propiedades.
En la venta que se abre seleccionamos, en la pestaña “Asociación“, los métodos de autenticación y cifrado que hemos definido:
 En la pestaña “Autenticación” seleccionamos “PEAP” como tipo de EAP y vamos a “Propiedades“:
En la pestaña “Autenticación” seleccionamos “PEAP” como tipo de EAP y vamos a “Propiedades“:
 En la ventana que se abre eliminamos la selección de “Utilizar certificado cliente” y en el método de autenticación “EAP-MSCHATP v2” vamos a “Configurar”, eliminando en la ventana que se abre la opción que viene señalada por defecto.
En la ventana que se abre eliminamos la selección de “Utilizar certificado cliente” y en el método de autenticación “EAP-MSCHATP v2” vamos a “Configurar”, eliminando en la ventana que se abre la opción que viene señalada por defecto.
 Aceptamos todos los cambios hacia atrás y guardamos la configuración. A los pocos segundos veremos este aviso:
Aceptamos todos los cambios hacia atrás y guardamos la configuración. A los pocos segundos veremos este aviso:
 Parece que funciona 😛 . Pinchamos en el aviso y nos salta la venta que buscamos:
Parece que funciona 😛 . Pinchamos en el aviso y nos salta la venta que buscamos:
 Introducimos nuestro usuario y clave de Radius y padentro!
Introducimos nuestro usuario y clave de Radius y padentro!
Eso es todo, hemos conseguido el objetivo del artículo, utilizar la misma infraestructura de autentificación para el entorno inalámbrico que la que teníamos para el acceso remoto por VPN.