Vamos con uno de esos artículos que le gustan a Álvaro basados en experiencias del trabajo.
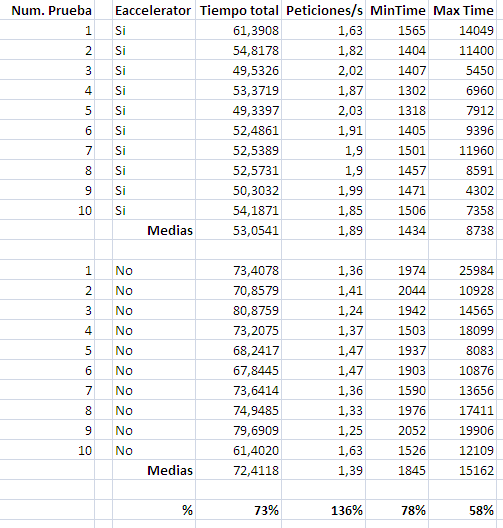
En uno de los proyectos en los que estamos trabajando actualmente y del que ya os he hablado, teníamos un problema de rendimiento en una aplicación web, pero no teníamos localizado el punto donde se nos iba el tiempo. Incluso había momentos que la aplicación iba bien pero en otros era lamentable. Se nos ocurrió, entonces, hacer un sencillo sistema de monitorización de los distintos puntos sensibles que manejábamos y crear con ellos una serie de gráficas que nos permitiese hacer un seguimiento visual de los potenciales problemas.
Nuestra aplicación se basa en llamadas a distintos webservices a partir de las cuales se genera un XML al que se le aplican transformaciones XSL para obtener el código html que se muestra al usuario. Algunas de esas llamadas se guardan en la sesión del usuario, con lo que en sucesivos accesos a la aplicación el rendimiento es infinitamente mejor, así que necesitábamos que el control se hiciese con sesiones limpias para que no se nos desvirtuasen las gráficas.
Nuestro sistema consiste en generar por un lado, en la aplicación web, una serie de datos estadísticos que nos ayuden a buscar los puntos conflictivos. Estos datos se insertarán periódicamente en una base de datos rrd (round robin database) que finalmente utilizaremos para generar las gráficas.
Preparando la aplicación web
El primer paso es, entonces, modificar el código de la aplicación para que vaya generando los tiempos de respuesta en los distintos puntos que queremos controlar. Para facilitar las cosas decidimos que cada vez que se pase un parámetro predefinido en la url, en vez de mostrar la página html correspondiente mostraremos las estadísticas que después controlaremos. En nuestro caso decidimos que la url de estadísticas fuese:
http://tudominio.com/index.php?stats
Es decir, añadiendo el parámetro stats a cualquiera de las urls del site obtendremos los tiempos de respuesta que necesitamos.
Tenemos una función que genera el tiempo exacto del servidor cada vez que se llama, así que la utilizaremos después de ejecutar cada uno de los webservices y guardaremos esos datos. En mi caso tengo que obtener ocho puntos de control además del tiempo de inicio y el tiempo final, algo así:
function getTime() {
$mtime2 = explode(" ", microtime());
$endtime = $mtime2[0] + $mtime2[1];
return $endtime;
}
$isStats=isset($_GET['stats']);
if($isStats)
$time_inicio=getTime();
....
if($isStats)
$time_ws1=getTime();
.....
if($isStats)
$time_ws2=getTime();
....
if($isStats)
$time_ws3=getTime();
....
if($isStats)
$time_ws4=getTime();
....
if($isStats)
$time_ws5=getTime();
....
if($isStats)
$time_ws6=getTime();
....
if($isStats)
$time_ws7=getTime();
....
if($isStats)
$time_ws8=getTime();
....
if($isStats)
$time_final=getTime();
......
Finalmente devolvemos una línea con todos los valores intermedios, es decir, para cada indicador sería el valor del tiempo de ese indicador menos el del anterior, esto nos dará el valor real del tiempo que ha pasado entre el indicador anterior y el actual. Para facilitar la posterior integración de estos valores con rrdtool lo que haremos será generarlos ya en el formato adecuado, separando cada valor con “:”.
if(isset($_GET['stats'])){
echo number_format($time_ws1-$time_inicio, 7).":".
number_format($time_ws2-$time_ws1, 7).":".
number_format($time_ws3-$time_ws2, 7).":".
number_format($time_ws4-$time_ws3, 7).":".
number_format($time_ws5-$time_ws4, 7).":".
number_format($time_ws6-$time_ws5, 7).":".
number_format($time_ws7-$time_ws6, 7).":".
number_format($time_ws8-$time_ws7, 7).":".
number_format($time_final-$time_inicio, 7);
}
Si ahora llamamos a nuestra url obtendremos los valores de nuestros indicadores. El último valor nos devolverá el tiempo completo de ejecución del script entre los valores $time_inicio y $time final.
0.0281749:0.5443010:0.3132501:2.9015441:0.0000241:0.6517198:5.5171580:0.0000379:10.0677590
Vemos cómo esta llamada ha tardado diez segundos, de los cuales 5,5 corresponden al indicador ws7.
Tenemos el primer paso preparado, vamos ahora a crear la base de datos donde almacenaremos toda la información estadística de la url. Tendremos una tarea que se ejecutará cada minuto y que recuperará los valores en ese momento de los identificadores que se han definido.
Creando la base de datos
Para guardar la información he escogido rrd, el mismo que utilizan aplicaciones como mrtg o Cacti y el utilizado en la mayoría de sistemas de monitorización. Según reza en su propia web, es el sistema estándar para gráficas y logs de series de datos temporales.
Para que todo vaya bien nuestra base de datos rrd debe tener la misma cantidad de fuentes de datos que el sistema de estadísticas, nueve en este caso, los ocho puntos de control más el total. Además tenemos que pensar qué graficas vamos a crear. Yo quiero cuatro: última hora, últimas seis horas, últimas 24 horas y última semana. No necesito hacer un sistema con histórico avanzado, lo que quiero en este caso es controlar el rendimiento, así que no necesitaré gráficas mensuales ni anuales, pero se podrían generar de igual modo.
Para crear nuestro archivo rrd ejecutamos el comando siguiente:
rrdtool create estadisticas.rrd --step 60 DS:ws1:GAUGE:120:0:U DS:ws2:GAUGE:120:0:U DS:ws3:GAUGE:120:0:U DS:ws4:GAUGE:120:0:U DS:ws5:GAUGE:120:0:U DS:ws6:GAUGE:120:0:U DS:ws7:GAUGE:120:0:U DS:ws8:GAUGE:120:0:U DS:total:GAUGE:120:0:U RRA:AVERAGE:0.5:1:60 RRA:AVERAGE:0.5:1:360 RRA:AVERAGE:0.5:5:144 RRA:AVERAGE:0.5:10:202 RRA:MAX:0.5:1:60 RRA:MAX:0.5:1:360 RRA:MAX:0.5:5:144 RRA:MAX:0.5:10:202 RRA:MIN:0.5:1:60 RRA:MIN:0.5:1:360 RRA:MIN:0.5:5:144 RRA:MIN:0.5:10:202
Vamos a explicarlo un poco.
- –step=60: indica que los datos los actualizaremos cada 60 segundos. Nuestro sistema guardará estadísticas cada minuto.
- DS:ws1:GAUGE:120:0:U: Fuentes de datos, hay una línea de este tipo para cada valor que vamos a mantener.
- wsX es el nombre que tendrá esa fuente.
- GAUGE es el tipo de fuente de datos, puedes consultar la documentación completa para tener más idea.
- 120 es el parámetro heartbeat, tiempo máximo entre dos actualizaciones antes de que se asuma que es desconocido. He puesto el doble de step, si pasado ese tiempo no hay una actualización es que se ha perdido por cualquier razón.
- Los últimos datos son los valores mínimo y máximo que habrá en la fuente de datos. En nuestro caso el mínimo será cero y el máximo no lo sabemos, le ponemos U de unknown.
- RRA:AVERAGE:0.5:1:60: Round robin archives. El objetivo de una rrd es guardar datos en los rra que mantienen valores y estadísticas para cada una de las fuentes de datos definidas.
- AVERAGE/MAX/MIN/LAST: la función utilizada para consolidar los datos. Como su propio nombre indica son la media, máximo, mínimo y el último valor.
- 0.5; el xff (xfiles factor). De 0 a 1, indica el número de datos UNKNOWN que se permiten por intervalo de consolidación.
- 1: define el número de datos utilizados para crear un intervalo de consolidación.
- 60: Cuantos datos se mantienen en cada RRA. Esto depende de la gráfica que vamos a generar y se relaciona con el dato anterior.
La última parte es la más complicada de comprender. Intentaré explicarlo lo mejor que pueda para que se entienda. En nuestro caso tomamos un dato cada 60 segundos y queremos tener la gráfica de la última hora (60 segundos x 60 minutos, 3600 segundos). Necesitamos, por tanto, 60 puntos de control (3600/60 segundos de intervalo), utilizaremos cada uno de los datos que se toman. Esto es lo que indica la creación RRA:AVERAGE:0.5:1:60, queremos utilizar 60 puntos de control tomados cada 60 segundos. Este es bastante fácil, veamos el siguiente.
RRA:MIN:0.5:1:360
Ahora estamos guardando 360 puntos generados cada 60 segundos, es decir, cubrimos 60×360=21600 segundos=6 horas. Era sencillo.
RRA:AVERAGE:0.5:5:144
En la siguiente gráfica queremos obtener datos de las últimas doce horas (12 horas x 60 minutos x 60 segundos, 43200 segundos). Ahora ya no necesitamos saber el comportamiento exacto en cada momento sino que necesitamos una visión global de lo que ha ocurrido durante esas doce horas, tomamos, por tanto, un punto de control cada cinco datos de registro, es decir, estamos manteniendo un dato cada 5×60 segundos, 300 segundos. Necesitaremos por tanto 43200/300=144 valores para obtener nuestra gráfica de las últimas 12 horas
RRA:MIN:0.5:10:202
La última gráfica es semanal, 7x24x60x60=604800 segundos. Acepto que con tener un valor cada 10 minutos será suficiente, tendré entonces un valor cada 10×300=3000 segundos. 604800/3000=~202.
Es algo difícil de entender al principio, pero una vez lo piensas, todo tiene sentido.
Guardando las estadísticas
Tenemos ya nuestra base de datos preparada, creemos ahora la tarea que guardará en este archivo rrd los datos estadísticos. En mi caso es una tarea PHP que lo hace todo muy sencillo.
tarea.php
$url="http://dominio.com/?stats";
$cont=file_get_contents($url);
system("rrdtool update estadisticas.rrd N:".$cont);
Añadimos la tarea al cron para que se ejecute cada 60 seguntos.
*/1 * * * * /usr/bin/php /path/to/tarea.php > /dev/null 2>&1
¡Y ya está! Nuestra base de datos de estadísticas se está alimentando automáticamente.
Creando las gráficas
Lo más importante a fin de cuentas, lo que realmente vamos a utilizar. Rrdtool viene con un script de ejemplo que debes colocar en el directorio cgi-bin de tu servidor web y realizar los ajustes adecuados. Yo he puesto como ejemplo la gráfica de la última hora, las demás se harían igual variando el parámetro “–start” a los segundos anteriores que queremos mostrar.
/cgi-bin/stats.cgi
#!/usr/bin/rrdcgiTu Dominio - Home Stats
<RRD::GRAPH /usr1/www/www.genteirc.com/htdocs/imagenes/daily-visitas.png --imginfo '<img src="http://tudominio.com/%s" alt="" width="%lu" height="%lu" />' --start -3600 --end -0 -h 400 -w 600 --vertical-label="Tiempo" --title="Last Hour" -a PNG -l 0 DEF:ws1=/path/to/estadisticas.rrd:ws1:AVERAGE LINE1:ws1#00FF00:WebSer1t GPRINT:ws1:AVERAGE:"Media : %.4lft" GPRINT:ws1:MAX:"Max : %.4lft" GPRINT:ws1:MIN:"Min : %.4lfl" DEF:ws2=/path/to/estadisticas.rrd:ws2:AVERAGE LINE1:ws2#800000:WebSer2t GPRINT:ws2:AVERAGE:"Media : %.4lft" GPRINT:ws2:MAX:"Max : %.4lft" GPRINT:ws2:MIN:"Min : %.4lfl" DEF:ws3=/path/to/estadisticas.rrd:ws3:AVERAGE LINE1:ws3#FF8000:WebSer3t GPRINT:ws3:AVERAGE:"Media : %.4lft" GPRINT:ws3:MAX:"Max : %.4lft" GPRINT:ws3:MIN:"Min : %.4lfl" DEF:ws4=/path/to/estadisticas.rrd:ws4:AVERAGE LINE1:ws4#400080:WebSer4t GPRINT:ws4:AVERAGE:"Media : %.4lft" GPRINT:ws4:MAX:"Max : %.4lft" GPRINT:ws4:MIN:"Min : %.4lfl" DEF:ws5=/path/to/estadisticas.rrd:ws5:AVERAGE LINE1:ws5#0000FF:WebSer5t GPRINT:ws5:AVERAGE:"Media : %.4lft" GPRINT:ws5:MAX:"Max : %.4lft" GPRINT:ws5:MIN:"Min : %.4lfl" DEF:ws6=/path/to/estadisticas.rrd:ws6:AVERAGE LINE1:ws6a#00FFF0:WebSer6t GPRINT:ws6a:AVERAGE:"Media : %.4lft" GPRINT:ws6:MAX:"Max : %.4lft" GPRINT:ws6:MIN:"Min : %.4lfl" DEF:ws7=/path/to/estadisticas.rrd:ws7:AVERAGE LINE1:ws7#FF00FF:WebSer7t GPRINT:ws7:AVERAGE:"Media : %.4lft" GPRINT:ws7:MAX:"Max : %.4lft" GPRINT:ws7:MIN:"Min : %.4lfl" DEF:ws8=/path/to/estadisticas.rrd:ws8:AVERAGE LINE1:ws8#FFFF00:WebSer8t GPRINT:ws8:AVERAGE:"Media : %.4lft" GPRINT:ws8:MAX:"Max : %.4lft" GPRINT:ws8:MIN:"Min : %.4lfl" DEF:total=/path/to/estadisticas.rrd:total:AVERAGE LINE2:total#FF0000:'Total t' GPRINT:total:AVERAGE:"Media : %.4lft" GPRINT:total:MAX:"Max : %.4lft" GPRINT:total:MIN:"Min : %.4lfl" >
Para cada línea que queremos mostrar en la gráfica le indicamos de qué archivo rrd saldrán los datos y la fuente (DS) que vamos a utilizar. Añadimos además como leyenda los datos de media, máximo y mínimo de cada fuente, de manera que en una sola gráfica tenemos toda la información necesaria. Si ahora vas a la url donde has dejado el cgi tendrás:
http://tudominio.com/cgi-bin/stats.cgi

Y tu te preguntarás, con lo pesado que te pones con Cacti, ¿por qué no meterla ahí también? Buena pregunta :P. Si tengo un ratito os enseño cómo integrarlo también con Cacti :).
Me he pasado con este artículo, no se lo va a leer nadie :P.